Scalable Architectures
Jakob Jenkov |
A scalable architecture is an architecture that can scale up to meet increased work loads. In other words, if the work load all of a sudden exceeds the capacity of your existing software + hardware combination, you can scale up the system (software + hardware) to meet the increased work load.
Scalability Factor
When you scale up your system's hardware capacity, you want the workload it is able to handle to scale up to the same degree. If you double hardware capacity of your system, you would like your system to be able to handle double the workload too. This situation is called "linear scalability".
Linear scalability is often not the case though. Very often there is an overhead associated with scaling up, which means that when you double hardware capacity, your system can handle less than double the workload.
The extra workload your system can handle when you scale up your hardware capacity is your system's scalability factor. The scalability factor may vary depending on what part of your system you scale up.
Vertical and Horizontal Scalability
There are two primary ways to scale up a system: Vertical scaling and horizontal scaling.
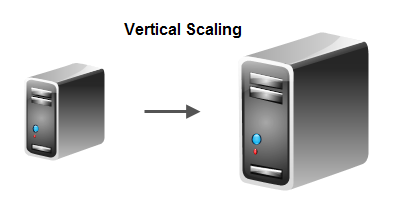
Vertical scaling means that you scale up the system by deploying the software on a computer with higher capacity than the computer it is currently deployed on. The new computer may have a faster CPU, more memory, faster and larger hard disk, faster memory bus etc. than the current computer.
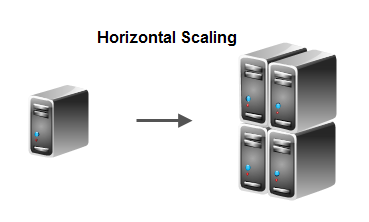
Horizontal scaling means that you scale up the system by adding more computers with your software deployed on. The added computers typically have about the same capacity as the current computers the system is running on, or whatever capacity you would get for the same money at the time of purchase (computers tend to get more powerful for the same money over time).
Architecture Scalability Requirements
The easiest way to scale up your software from a developer perspective is vertical scalability. You just deploy on a bigger machine, and the software performs better. However, once you get past standard hardware requirements, buying faster CPUs, bigger and faster RAM modules, bigger and faster hard disks, faster and bigger motherboards etc. gets really, really expensive compared to the extra performance you get. Also, if you add more CPUs to a computer, and your software is not explicitly implemented to take advantage of them, you will not get any increased performance out of the extra CPUs.
Scaling horizontally is not as easy seen from a software developer's perspective. In order to make your software take advantage of multiple computers (or even multiple CPUs within the same computer), your software need to be able to parallelize its tasks. In fact, the better your software is at parallelizing its tasks, the better your software scales horizontally.
Task Parallelization
Parallelization of tasks can be done at several levels:
- Distributing separate tasks onto separate computers.
- Distributing separate tasks onto separate CPUs on the same computer.
- Distributing separate tasks onto separate threads on the same CPU.
You may also take advantage of special hardware the computers might have, like graphics cards with lots of CPU cores, or InfiniBand network interface cards etc.

Distributing separate tasks to separate computers is often referred to as "load balancing". Load balancing will be covered in more detail in a separate text.
Executing multiple different applications on the same computer, possible using the same CPU or using different CPUs is referred to as "multitasking". Multitasking is typically done by the operating system, so this is not something software developers need to think too much about. What you need to think about is how to break your application into smaller, independent but collaborating processes, which can also be distributed onto different CPUs or even computers if needed.
Distributing tasks inside the same application to different threads is referred to as "multithreading". I have a separate tutorial on Java Multithreading so I will not get deeper into multithreading here.
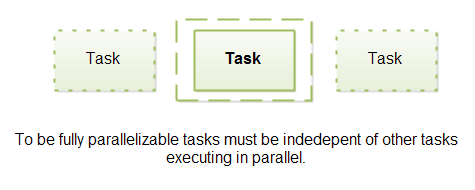
To be fully parallelizable, a task must be independent of other tasks executing in parallel with it.
To be fully distributable onto any computer, the task must contain, or be able to access, any data needed to execute the task, regardless of what computer executes the task. Exactly what that means depends on the kind of application you are developing, so I cannot get into deeper detail here.
| Tweet | |
Jakob Jenkov | |










