Java NIO: Non-blocking Server
Jakob Jenkov |
Even if you understand how the Java NIO non-blocking features work (Selector, Channel,
Buffer etc.), designing a non-blocking server is still hard. Non-blocking IO contains several
challenges compared blocking IO. This non-blocking server tutorial will discuss the major challenges
of non-blocking servers, and describe some potential solutions for them.
Finding good information about designing non-blocking servers is hard. Therefore the solutions provided in this tutorial are based on my own work and ideas. If you have some alternative or even better ideas, I would be happy to hear about them! You can write a comment under the article or send me an email (see our About page), or catch me on Twitter.
The ideas described in this tutorial are designed around Java NIO. However, I believe that the ideas can be
reused in other languages as long as they have some kind of Selector-like construct. As far as I know,
such constructs are provided by the underlying OS, so there is a good chance that you can get access to this in
other languages too.
Non-blocking Server - GitHub Repository
I have created a simple proof-of-concept of the ideas presented in this tutorial and put it in a GitHub repository for you to look at. Here is the GitHub repository:
https://github.com/jjenkov/java-nio-server
Non-blocking IO Pipelines
A non-blocking IO pipeline is a chain of components that process non-blocking IO. This includes both reading and writing IO in a non-blocking fashion. Here is an illustration of a simplified non-blocking IO pipeline:
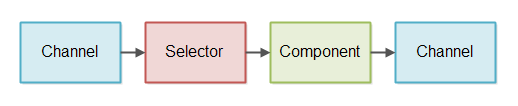
A component uses an Selector to check when a Channel
has data to read. Then the component reads the input data and generates some output based on the input. The output
is written to a Channel again.
A non-blocking IO pipeline does not need to both read and write data. Some pipelines may only read data, and some pipelines may only write data.
The above diagram only shows a single component. A non-blocking IO pipeline may have more than one component process incoming data. The length of a non-blocking IO pipeline depends on what the pipeline needs to do.
A non-blocking IO pipeline may also be reading from multiple Channels at the same time. For instance,
reading data from multiple SocketChannels.
The flow of control in the above diagram is also simplified. It is the component that initiates the reading
of data from the Channel via the Selector. It is not the Channel that pushes
the data into the Selector and from there into the component, even if that is what the above diagram
suggests.
Non-blocking vs. Blocking IO Pipelines
The biggest difference between a non-blocking and a blocking IO pipeline is how data is read from the underlying
Channel (socket or file).
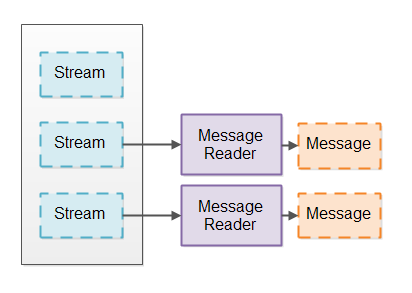
IO pipelines typically read data from some stream (from a socket or file) and split that data into coherent messages. This is similar to breaking a stream of data into tokens for parsing using a tokenizer. Instead, you break the stream of data into bigger messages. I will call the component breaking the stream into messages for a Message Reader. Here is an illustration of a Message Reader breaking a stream into messages:

A blocking IO pipeline can use an InputStream-like interface
where one byte at a time can be read from the underlying Channel, and where the InputStream-like
interface blocks until there is data ready to read. This results in a blocking Message Reader implementation.
Using a blocking IO interface to a stream simplifies the implementation of a Message Reader a lot. A blocking Message Reader never has to handle situations where no data was read from the stream, or where only a partial message was read from the stream and message parsing needs to be resumed later.
Similarly, a blocking Message Writer (a component that writes messages to a stream) never has to handle the situation where only part of a message was written, and where message writing has to be resumed later.
Blocking IO Pipeline Drawbacks
While a blocking Message Reader is easier to implement, it has the unfortunate drawback of requiring a separate thread for each stream that needs to be split into messages. The reason this is necessary is that the IO interface of each stream blocks until there is some data to read from it. That means that a single thread cannot attempt to read from one stream, and if there is no data, read from another stream. As soon as a thread attempts to read data from a stream, the thread blocks until there is actually some data to read.
If the IO pipeline is part of a server which has to handle lots of concurrent connections, the server will need one thread per active ingoing connection. This may not be a problem if the server only has a few hundred concurrent connections at any time. But, if the server has millions of concurrent connections, this type of design does not scale so well. Each thread will take between 320K (32 bit JVM) and 1024K (64 bit JVM) memory for its stack. So, 1.000.000 threads will take 1 TB memory! And that is before the server has used any memory for processing the incoming messages (e.g. memory allocated for objects used during message processing).
To keep the number of threads down, many servers use a design where the server keeps a pool of threads (e.g. 100) which reads messages from the inbound connections one at a time. The inbound connections are kept in a queue, and the threads process messages from each inbound connection in the sequence the inbound connections are put into the queue. This design is illustrated here:
However, this design requires that the inbound connections send data reasonably often. If the inbound connections may be inactive for longer periods, a high number of inactive connections may actually block all the threads in the thread pool. That means that the server becomes slow to respond or even unresponsive.
Some server designs try to mitigate this problem by having some elasticity in the number of threads in the thread pool. For instance, if the thread pool runs out of threads, the thread pool might start more threads to handle the load. This solution means that it takes a higher number of slow connections to make the server unresponsive. But remember, there is still an upper limit to how many threads you can have running. So, this would not scale well with 1.000.000 slow connections.
Basic Non-blocking IO Pipeline Design
A non-blocking IO pipeline can use a single thread to read messages from multiple streams. This requires that the streams can be switched to non-blocking mode. When in non-blocking mode, a stream may return 0 or more bytes when you attempt to read data from it. The 0 bytes is returned if the stream has no data to read. The 1+ bytes are returned when the stream actually has some data to read.
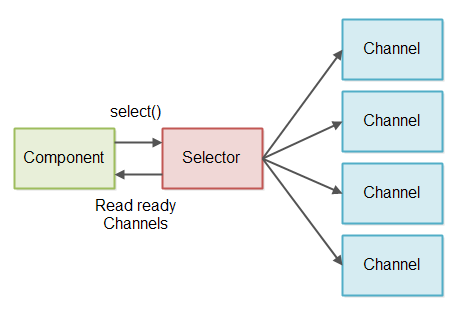
To avoid checking streams that has 0 bytes to read we use a Java NIO Selector.
One or more SelectableChannel instances can be registered with a Selector. When you
call select() or selectNow() on the Selector it gives you only the
SelectableChannel instances that actually has data to read. This design is illustrated here:
Reading Partial Messages
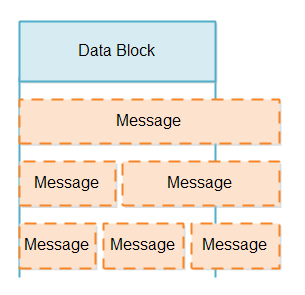
When we read a block of data from a SelectableChannel we do not know if that data block contains
less or more than a message. A data block could potentially contain a partial message (less than a message),
a full message, or more than a message, for instance 1.5 or 2.5 messsages. The various partial message
possibilities are illustrated here:
There are two challenges in handling partial messages:
- Detecting if you have a full message in the data block.
- What to do with partial messages until the rest of the message arrives.
Detecting full messages requires that the Message Reader looks at the data in the data block to see if the data contains at least one full message. If the data block contains one or more full messages, these messages can be sent down the pipeline for processing. The process of looking for full messages will be repeated a lot, so this process has to be as fast as possible.
Whenever there is a partial message in a data block, either by itself or after one or more full messages,
that partial message needs to be stored until the rest of that message arrives from the Channel.
Both detecting full messages and storing partial messages is the responsibility of the Message Reader. To avoid
mixing message data from different Channel instances we will use one Message Reader per Channel.
The design looks like this:
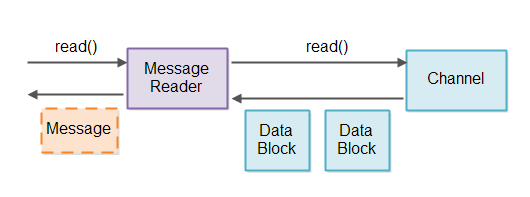
After retrieving a Channel instance which has data to read from the Selector,
the the Message Reader associated with that Channel reads data and attempt to break it it into messages.
If that results in any full messages being read, these message can be passed down the read pipeline to whatever
component needs to process them.
A Message Reader is of course protocol specific. A Message Reader needs to know the message format of the messages it is trying to read. If our server implementation is to be reusable across protocols, it needs to be able to have the Message Reader implementation plugged in - possibly by accepting a Message Reader factory as configuration parameter somehow.
Storing Partial Messages
Now that we have established that it is the responsibility of the Message Reader to store partial messages until a full message has been received, we need to figure out how this partial message storage should be implemented.
There are two design considerations we should take into consideration:
- We want to copy message data around as little as possible. The more copying, the lower performance.
- We want full messages to be stored in consecutive byte sequences to make parsing messages easier.
A Buffer Per Message Reader
Obviously the partial messages need to be stored in some kind of buffer. The straightforward implementation would be to simply have one buffer internally in each Message Reader. However, how big should that buffer be? It would need to be big enough to be able to store even the biggest allowed messages. So, if the biggest allowed message is 1MB, then the internal buffer in each Message Reader would need to be at least 1MB.
Using 1MB per connection doesn't really work when we reach millions of connections. 1.000.000 x 1MB is still 1TB memory! And what if the maximum message size is 16MB? Or 128MB ?
Resizable Buffers
Another option would be to implement a resizable buffer for use inside each Message Reader. A resizable buffer will start small, and if a message gets too big for the buffer, the buffer is expanded. This way each connection will not necessarily require an e.g. 1MB buffer. Each connection only takes as much memory as they need to hold the next message.
There are several ways to implement a resizable buffer. All of them have advantages and disadvantages, so I will discuss them all in the following sections.
Resize by Copy
The first way to implement a resizable buffer is to start with a small buffer of e.g. 4KB. If a message cannot fit into the 4KB buffer, a larger buffer of e.g. 8KB could be allocated, and the data from the 4KB buffer copied into the bigger buffer.
The advantage of the resize-by-copy buffer implementation is that all data for a message is kept together in a single consecutive byte array. This makes parsing the message much easier.
The disadvantage of the resize-by-copy buffer implementation is that it will lead to a lot of data copying for bigger messages.
To reduce data copying you could analyze the size of the messages flowing through your system to find some buffer sizes that would reduce the amount of copying. For instance, you might see that most messages are less than 4KB because they only contain very small requests / responses. That means that the first buffer size should be 4KB.
Then you might see that if a message is larger than 4KB it is often because it contains a file. You might then notice that most of the files flowing through the system is less than 128KB. Then it makes sense to make the second buffer size 128KB.
Finally you might see that once a message is above 128KB there is no real pattern in how large the message is, so perhaps the final buffer size should just be the maximum message size.
With these 3 buffer sizes based on the size of messages flowing through your system, you will have reduced data copying somewhat. Messages below 4KB will never be copied. For 1.000.000 concurrent connections that results in 1.000.000 x 4KB = 4GB which is possible in most servers today (2015). Messages between 4KB and 128KB will get copied once, and only 4KB data will need to be copied into the 128KB buffer. Messages between 128KB and maximum message size will be copied twice. First time 4KB will get copied, second time 128KB will get copied, so a total of 132KB copying for the biggest messages. Assuming that there are not that many messages above 128KB this might be acceptable.
Once a message has been fully processed the allocated memory should be freed again. That way the next message received from the same connection starts with the smallest buffer size again. This is necessary to make sure that the memory can be shared more efficiently between connections. Most likely not all connections will need big buffers at the same time.
I have a complete tutorial about how to implement such a memory buffer that supports resizable arrays here: Resizable Arrays . The tutorial also contains a link to a GitHub repository with code showing a working implementation.
Resize by Append
Another way to resize a buffer is to make the buffer consist of multiple arrays. When you need to resize the buffer you simply allocate another byte array and write the data into that.
There are two ways to grow such a buffer. One way is to allocate separate byte arrays and keep a list of these byte arrays. Another way is to allocate slices of a larger, shared byte array, and then keep a list of the slices allocated to the buffer. Personally, I feel the slices approach is slightly better, but the difference is small.
The advantage of growing a buffer by appending separate arrays or slices to it is that no data needs to be copied
during writing. All data can be copied directly from a socket (Channel) directly into an array or
slice.
The disadvantage of growing a buffer this way is that the data is not stored in a single, consecutive array. This makes message parsing harder, since the parsers need to look out for both the end of every individual array and the end of all arrays at the same time. Since you need to look for the end of a message in the written data, this model is not too easy to work with.
TLV Encoded Messages
Some protocol message formats are encoded using a TLV format (Type, Length, Value). That means, that when a message arrives the total length of the message is stored in the beginning of the message. That way you know immediately how much memory to allocate for the whole message.
TLV encodings make memory management much easier. You know immediately how much memory to allocate for the message. No memory is wasted at the end of a buffer that is only partially used.
One disadvantage of TLV encodings is that you allocate all the memory for a message before all the data of the message has arrived. A few, slow connections sending big messages can thus allocate all the memory you have available, making your server unresponsive.
A workaround for this problem would be to use a message format that contains multiple TLV fields inside. Thus, memory is allocated for each field, not for the whole message, and memory is only allocated as the fields arrive. Still, a large field can have the same effect on your memory management as a large message.
Another workaround is to time out messages which have not been received within e.g. 10-15 seconds. This can make your server recover from a coincidental, simultaneous arrival of many big messages, but it will still make the server unresponsive for a while. Additionally, an intentional DoS (Denial of Service) attack can still result in full allocation of the memory for your server.
TLV encodings exist in different variations. Exactly how many bytes is used so specify the type and length of a field depends on each individual TLV encoding. There are also TLV encodings that put the length of the field first, then the type, and then the value (an LTV encoding). While the sequence of the fields is different, it is still a TLV variation.
The fact that TLV encodings makes memory management easier is one of the reasons why HTTP 1.1 is such a terrible protocol. That is one of the problems they are trying to fix in HTTP 2.0 where data is transported in LTV encoded frames. This is also why we have designed our own network protocol for our VStack.co project that uses a TLV encoding.
Writing Partial Messages
In a non-blocking IO pipeline writing data is also a challenge. When you call write(ByteBuffer) on a Channel
in non-blocking mode there is no guarantee about how many of the bytes in the ByteBuffer is being written.
The write(ByteBuffer) method returns how many bytes were written, so it is possible to keep track
of the number of written bytes. And that is the challenge: Keeping track of partially written messages so that in
the end all bytes of a message have been sent.
To manage the writing of partial messages to a Channel we will create a Message Writer. Just like
with the Message Reader, we will need a Message Writer per Channel we write messages to.
Inside each Message Writer we keep track of exactly how many bytes have been written of the message it is currently
writing.
In case more messages arrives for a Message Writer than it can write directly
out to the Channel, the messages needs to be queued up internally in the Message Writer. The Message
Writer then writes the messages as fast as it can to the Channel.
Here is a diagram showing how the partial message writing is designed so far:
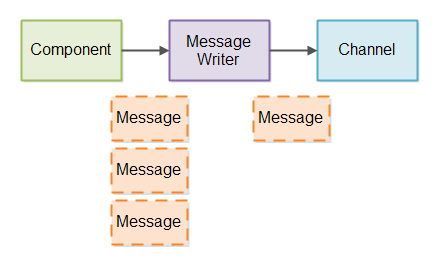
For the Message Writer to be able to send messages that were only partially sent earlier, the Message Writer needs to be called from time to time, so it can send more data.
If you have a lot of connections you will have a lot of Message Writer instances. Checking e.g. a million Message Writer
instances to see if they can write any data is slow. First of all, many of the Message Writer instance many not
have any messages to send. We don't want to check those Message Writer instances. Second, not all Channel
instances may be ready to write data to. We don't want to waste time trying to write data to a Channel
that cannot accept any data anyways.
To check if a Channel is ready for writing you can register the channel with a Selector.
However, we do not want to register all Channel instances with the Selector. Imagine
if you have 1.000.000 connections which are mostly idle and all 1.000.000 connections were registered
with the Selector. Then, when you call select() most of these Channel
instances would be write-ready (they are mostly idle, remember?). You would then have to check the Message Writer
of all those connections to see if they had any data to write.
To avoid checking all Message Writer instances for messages, and all Channel instances which anyways
do not have any messages to be sent to them, we use this two-step approach:
-
When a message is written to a Message Writer, the Message Writer registers its associated
Channelwith theSelector(if it is not already registered).
-
When your server has time, it checks the
Selectorto see which of the registeredChannelinstances are ready for writing. For each write-readyChannelits associated Message Writer is requested to write data to theChannel. If a Message Writer writes all its messages to itsChannel, theChannelis unregistered from theSelectoragain.
This little two-step approach makes sure that only Channel instances that have messages to be written to
them are actually registered with the Selector.
Putting it All Together
As you can see, a non-blocking server needs to check for incoming data from time to time to see if there are any new full messages received. The server might need to check multiple times until one or more full messages have been received. Checking one time is not enough.
Similarly, a non-blocking server needs to check from time to time if there is any data to write. If yes, the server needs to check if any of the corresponding connections are ready to have that data written to them. Checking only when a message is queued up the first time is not enough, since the message might be written partially.
All in all a non-blocking server ends up with three "pipelines" it needs to execute regularly:
- The read pipeline which checks for new incoming data from the open connections.
- The process pipeline which processes any full messages received.
- The write pipeline which checks if it can write any outgoing messages to any of the open connections.
These three pipelines are executed repeatedly in a loop. You might be able to optimize the execution somewhat. For instance, if there are no messages queued up you can skip the write pipeline. Or, if there we no new, full messages received, perhaps you can skip the process pipeline.
Here is a diagram illustrating the full server loop:
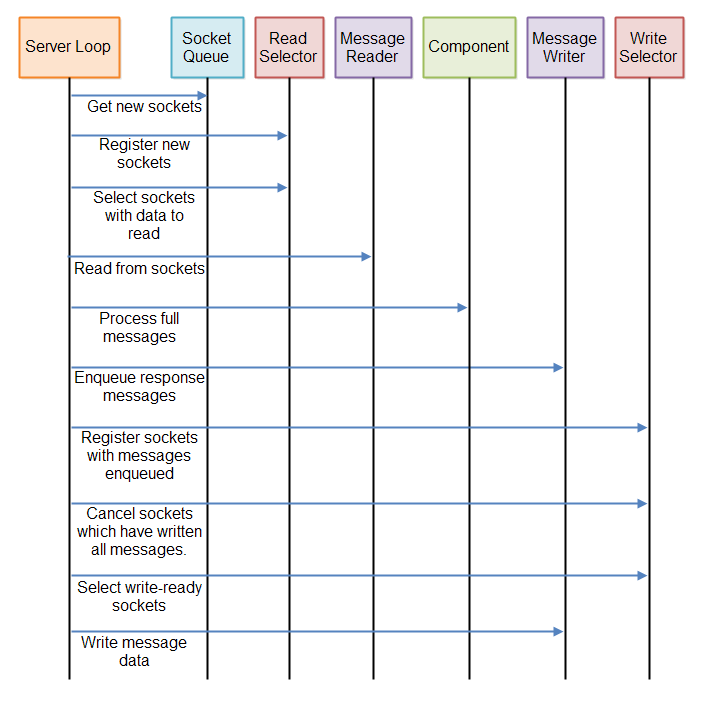
If you still find this a bit complicated, remember to check out the GitHub repository:
https://github.com/jjenkov/java-nio-server
Maybe seeing the code in action might help you understand how to implement this.
Server Thread Model
The non-blocking server implementation in the GitHub repository uses a thread model with 2 threads.
The first thread accepts incoming connections from a ServerSocketChannel. The second thread processes
the accepted connections, meaning reading messages, processing the messages and writing responses back to the
connections. This 2 thread model is illustrated here:
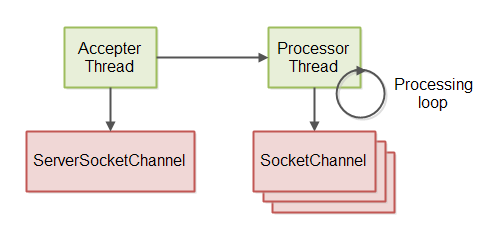
The server processing loop explained in the previous section is executed by the processing thread.
| Tweet | |
Jakob Jenkov | |










