False Sharing in Java
Jakob Jenkov |
False sharing in Java occurs when two threads running on two different CPUs write to two different variables which happen to be stored within the same CPU cache line. When the first thread modifies one of the variables - the whole CPU cache line is invalidated in the CPU caches of the other CPU where the other thread is running. This means, that the other CPUs need to reload the content of the invalidated cache line - even if they don't really need the variable that was modified within that cache line.
False Sharing in Java Tutorial Video
If you prefer video, I have a video version of false sharing in Java tutorial here: False Sharing in Java

False Sharing Illustration
Here is a diagram illustrating false sharing in Java:
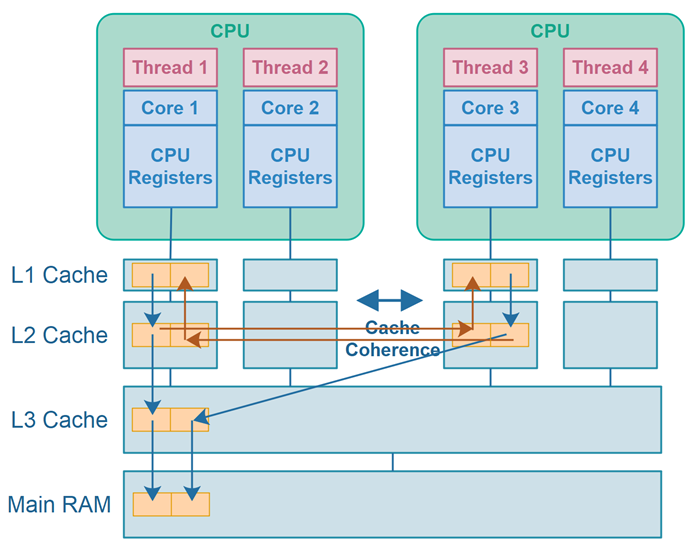
The diagram shows two threads running on different CPUs which write to different variables - with the variables being stored within the same CPU cache line - causing false sharing.
Cache Lines
When the CPU caches are reading data from lower level caches or main RAM (e.g. L1 from L2, L2 from L3 and L3 from main RAM), they don't just read a single byte at a time. That would be inefficient. Instead they read a cache line. A cache line typically consists of 64 bytes. Thus, the caches read 64 bytes at a time from lower level caches or main RAM.
Because a cache line consist of multiple bytes, a single cache line will often store more than one variable. If the same CPU needs to access more of the variables stored within the same cache line - this is an advantage. If multiple CPUs need to access the variables stored within the same cache line, false sharing can occur.
Cache Line Invalidation
When a CPU writes to memory address in a cache line, typically because the CPU is writing to a variable, the cache line becomes dirty. The cache line then needs to be synchronized to other CPUs that also have that cache line in their CPU caches. The same cache line stored in the other CPU caches thus becomes invalid - they need to be refreshed, in other words.
In the diagram above, making a cache line dirty is represented by the blue lines, and cache line invalidation is represented by the red arrows.
Cache refreshing after cache invalidation can happen either via cache coherence mechanisms, or by reloading the cache line from main RAM.
The CPU is not allowed to access that cache line until it has been refreshed.
False Sharing Results in a Performance Penalty
When a cache line is invalidated because data inside that cache line has been changed by another CPU, then the invalidated cache line needs to be refreshed - either from the L3 cache, or via cache coherence mechanisms. Thus, if the CPU needs to read the invalidated cache line, it has to wait until the cache line is refreshed. This results in a performance degradation. The CPUs time is wasted waiting for cache line refresh - meaning the CPU can execute fewer instructions during that time.
False sharing means that two (or more) CPUs are writing to variables stored within the same cache line, but each CPU doesn't really rely on the value written by the other CPU. However, they are still both continually making the cache line dirty, causing it to invalidate for the other CPU, forcing the other CPU to refresh it - before the other CPU also makes the cache line dirty, causing the first CPU to have to refresh it etc.
The solution to false sharing is to change your data structures so the independent variables used by the CPUs are no longer stored within the same cache line.
Note: Even if the CPUs sometimes use the variable written to by the other CPU, you can still benefit from making sure the shared variables are not stored within the same cache line. Exactly how much, you will need to experiment to find out - in your concrete case.
False Sharing Java Code Example
The following two classes illustrate how false sharing can occur in a Java application.
The first class is a Counter class which is used by two threads. The first thread will increment
the count1 field, and the second thread will increment the count2 field.
public class Counter {
public volatile long count1 = 0;
public volatile long count2 = 0;
}
Here is a code example that starts 2 threads which increments the two counter fields within the same Counter instance:
public class FalseSharingExample {
public static void main(String[] args) {
Counter counter1 = new Counter();
Counter counter2 = counter1;
long iterations = 1_000_000_000;
Thread thread1 = new Thread(() -> {
long startTime = System.currentTimeMillis();
for(long i=0; i<iterations; i++) {
counter1.count1++;
}
long endTime = System.currentTimeMillis();
System.out.println("total time: " + (endTime - startTime));
});
Thread thread2 = new Thread(() -> {
long startTime = System.currentTimeMillis();
for(long i=0; i<iterations; i++) {
counter2.count2++;
}
long endTime = System.currentTimeMillis();
System.out.println("total time: " + (endTime - startTime));
});
thread1.start();
thread2.start();
}
}
On my laptop, running this example takes around 36 seconds.
If instead the code is changed so that each thread increments the fields of two different Counter instances (shown below), then the code only takes around 9 seconds to run. That is a factor 4 in difference between code with and without false sharing. That is quite a lot!
This speed difference is most likely caused by false sharing in the first example, where the count1
and count2 fields in the shared Counter instance are located within the same cache line at runtime.
In the second example (below) the two thread use each their own Counter instance, which are no longer storing
their fields within the same cache line. Thus, no false sharing occurs, and the code runs faster.
Here is the changed code. The only line that has been changed in the line marked in bold text:
public class FalseSharingExample {
public static void main(String[] args) {
Counter counter1 = new Counter();
Counter counter2 = new Counter();
long iterations = 1_000_000_000;
Thread thread1 = new Thread(() -> {
long startTime = System.currentTimeMillis();
for(long i=0; i<iterations; i++) {
counter1.count1++;
}
long endTime = System.currentTimeMillis();
System.out.println("total time: " + (endTime - startTime));
});
Thread thread2 = new Thread(() -> {
long startTime = System.currentTimeMillis();
for(long i=0; i<iterations; i++) {
counter2.count2++;
}
long endTime = System.currentTimeMillis();
System.out.println("total time: " + (endTime - startTime));
});
thread1.start();
thread2.start();
}
}
Fixing False Sharing Problems
The way to fix a false sharing problem is to design your code so that different variables used by different threads do not end up being stored within the same CPU cache line. Exactly how you do that depends on your concrete code, but storing the variables in different objects is one way to do so - as the example in the previous section showed.
Preventing False Sharing With the @Contented Annotation
From Java 8 and 9, Java has the @Contended annotation which can pad fields inside classes with empty bytes
(after the field - when stored in RAM), so that the fields inside an object of that class are not stored within
the same CPU cache line. Below is the Counter class
from the earlier example with the @Contended annotation added to one of the fields. Adding this
annotation made the execution time drop down to around the same time as when the two thread used two different
Counter instances. Here is the modified Counter class:
public class Counter1 {
@jdk.internal.vm.annotation.Contended
public volatile long count1 = 0;
public volatile long count2 = 0;
}
Annotating Classes with @Contended
You can use the @Contended above a class - to make all fields be padded from each other. However,
doing so in my example did not reduce execution time. Annotating the first field did. Make sure you
performance measure the different options before choosing one. Here is an example of annotating the
Counter class with the @Contended :
@jdk.internal.vm.annotation.Contended
public class Counter1 {
public volatile long count1 = 0;
public volatile long count2 = 0;
}
Annotating Fields with @Contented
You can use the @Contended above a field - to pad that field from other fields in the class.
Here is how annotating a field with @Contended looks:
public class Counter1 {
@jdk.internal.vm.annotation.Contended
public volatile long count1 = 0;
@jdk.internal.vm.annotation.Contended
public volatile long count2 = 0;
}
Grouping Fields
The @Contended annotation makes it possible to group fields so the grouped fields are kept close
together in RAM, but have padding between them and other fields in the class. Here is an example of
grouping fields with the @Contended annotation:
public class Counter1 {
@jdk.internal.vm.annotation.Contended("group1")
public volatile long count1 = 0;
@jdk.internal.vm.annotation.Contended("group1");
public volatile long count2 = 0;
@jdk.internal.vm.annotation.Contended("group2");
public volatile long count3 = 0;
}
In this example the fields count1 and count2 are grouped together in the same group
named group1 and the field count3 is located in its own group. Thus,
count1 and count2 will be kept close together in the class, but will have padding
in between them and the count3 field.
The group names don't matter except to match fields to groups.
Configuring the Padding Size
By default the @Contended annotations adds 128 bytes of padding after a field annotated with @Contended. However, you can tell the Java VM how many bytes to use as padding via JVM command line argument. Here is how that command line argument looks:
-XX:ContendedPaddingWidth=64
This argument configures the Java VM to use 64 bytes for padding with the @Contended annotation instead of 128 bytes.
The amount of padding bytes needed to avoid false sharing in Java depends on the underlying hardware architecture - meaning how many bytes each CPU cache line contains. If you know that, you can optimize the false sharing prevention padding to match the cache line size. Thus, if cache lines are only 64 bytes there is no reason to pad with 128 bytes. Additionally, if the cache lines are 256 bytes, padding with only 128 bytes will not be enough to prevent false sharing.
| Tweet | |
Jakob Jenkov | |










