Propagating the AppException
Jakob Jenkov |
As mentioned in the text Propagating Exceptions there are two ways to propagate an exception:
- Passive propagation
- Active propagation
Passive propagation pretty much just means to let the exception bubble up, without doing anything except closing opened resources. Thus, I will not touch upon that much more in this text. If you have nothing to add to an exception that is thrown from a deeper layer of code, just let it bubble up. Active propagation should only be used, if you have actually something to add to the exception.
Active propagation means catching the exception, add information to it, and rethrow it. Active propagations is also called "exception enrichment" - since the exception is enriched with information on the way up the call stack.
Here is an example:
public void loadConfigFile(String configFile) throws AppException {
try {
byte[] file = loadFile(configFile);
//do something with config file...
} catch (AppException e) {
ErrorInfo errorInfo = e.addInfo();
errorInfo.setErrorId ("ConfigFileLoad");
errorInfo.setContextId("ConfigFileLoader");
errorInfo.setSeverity (ErrorInfo.SEVERITY_FATAL);
errorInfo.setErrorType(ErrorInfo.ERROR_TYPE_INTERNAL);
errorInfo.setErrorDescription("Error loading config file: "
+ configFile);
errorInfo.setErrorCorrection ("Stop application, " +
"and check that the configuration file is present and valid");
errorInfo.getParameters().put("configFile", configFile);
throw e;
}
}
This example shows a loadConfigFile() method which calls the loadFile() method
shown in the previous text, Throwing the AppException.
The called loadFile() method throws an exception if the file cannot be found. However,
the loadFile() method does not know what kind of file is being loaded, and thus cannot
know if a load error is a serious error or not. Therefore, the loadFile() method will
just report the severity of the error as SEVERITY_ERROR.
The loadConfigFile() method however, knows that it is loading a very important configuration
file. Therefore, if the underlying loadFile() throws an AppException, this exception
is caught, and more information is added to it (a new ErrorInfo object is added). Here is what information
is updated:
- The
errorIdanderrorContextare updated to reflect what was being done and where, when the exception occurred (ConfigFileLoadandConfigFileLoader) -
The
severityis updated toSEVERITY_FATAL, since the configuration file must be present for the application to work. -
The
errorTypeis set toERROR_TYPE_INTERNAL, since a missing or invalid configuration file is definately an internal application problem. -
The
errorDescriptionanderrorCorrectionare updated to tell what the error is, and what can be done about it. TheloadConfigFile()method knows more about that, than theloadFile()method did, that threw theAppExceptionoriginally. -
The
configFileparameter is added to theErrorInfoparameters, just in caseloadFile()forgets to add the name of the failed file to it's ownErrorInfo.
Finally, the original AppException is rethrown. Rethrowing the AppException does not destroy the
original stack trace (at least not in Java). In Java, the stack trace is filled in when the exception is instantiated, not when it
is thrown. It is probably the same in Scala, since Scala runs on the Java VM. I don't know how this works in C#.
After the AppException as been rethrown, it now contains 2 ErrorInfo objects internally.
One from the loadFile() method, and one from the loadConfigFile() method. This is
illustrated here:
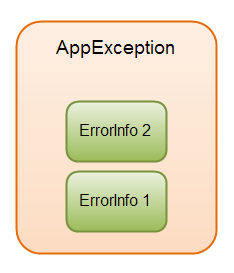 |
| An AppException with an ErrorInfo list internally. |
When to Add an ErrorInfo Object
You should not add an ErrorInfo object at every single propagation layer, on the way up the call stack.
Only add an ErrorInfo object if you have actually something new to say. Something to add to the original
exception.
For instance, you may have more information about what was attempted when the exception occurred - what parameters were used etc. If loading of a file fails, and thus results in an exception, you may add information about what kind of file was attempted loaded. Was it a fatal configuration file? Or was it a user who typed in the wrong file name for a file they wanted to load in the application?
What to set in the ErrorInfo Object
When you actively propagate an exception, you do not need to fill in every field in the new ErrorInfo
object added to the exception. It is only ncecessary to set the information that is actually new.
For instance, if you do not want to change the severity of the error, don't set it.
Just leave it empty in the new ErrorInfo object. Likewise, if you are throwing an exception
from some utility method, like loadFile(), you may not actually know what the proper error
correction is. That may depend on what part of your application that called the method. In that case,
just leave it empty (null).
Playing it Safe
Of course you can decide to play it safe, and set every field each time an exception is actively propagated. It is not wrong to do so. It just takes up some more code lines.
The advantage of setting every field every time is, that you do not depend on underlying fields to be set correctly.
For instance, if the loadFile() reported the severity as SEVERITY_FATAL already, you may
decide not to set the severity in the loadConfigFile() method. However, if the loadFile()
then one day is changed to set the severity to SEVERIY_ERROR, then the loadConfigFile() file
is no longer correct. It should then set the SEVERITY_FATAL explicitly then.
By alway setting each field explicitly, you avoid these kinds of dependency errors.
The Common Cases
Most often you will have only a single ErrorInfo object in the list, all the way up the call stack.
That is, you attempted some operation, and some part of it failed. The whole operation now has to be aborted.
The point where the part operation fails, will set the severity and error type.
If that point in the code can only be reached through one path in the code, you know that the error is
always of the same severity and type.
On the way up the call stack you may add additional ErrorInfo objects, which only add additional
parameters etc. to the exception. The error type and severity are often untouched.
Only if an exception can occur in a piece of code with multiple possible paths to the failing code, is it
necessary to update the error type and severity, depending on what context
the failing piece of code was called in.
For instance, a FileLoader component may be called both from a ConfigFileLoader,
and a UserFileLoader component. If the file loading fails, it depends on which component that
called it, how severe the error is, and what type it is.
Contrarily you may have an EmployeeDao which can insert Employee records in the database.
You may know that this EmployeeDao.insert() is only ever called from one other component.
Thus, it is always the same error type and severity if an exception occurs during insert. There is no
need to add extra information to the original ErrorInfo object, except perhaps a few extra parameters
further up the call stack, if relevant.
This may all sound a bit confusing, and it is, until you start using it in your own applications. Then, little by little it will be more and more clear to you how it works.
| Tweet | |
Jakob Jenkov | |










