Stream Processing API Designs
Jakob Jenkov |
Stream processing has become quite popular as a technique to process streams of incoming events or records as soon as they are received. There are many benefits of, and use cases for, stream processing (aka data streaming), and therefore several stream processing APIs have been developed to help developers process streams more easily.
On the surface these stream processing APIs look similar. However, once you try to implement complex stream processing topologies with these APIs, you realize that the design of these APIs have a quite large impact on just how "easy" processing streams with them becomes. Even subtle differences in design can have a big impact on what you can implement and especially how easy it is to do.
Having burned my own hands on various stream processing APIs, I decided to write this analysis of stream processing API designs to help anyone who is about to venture into stream processing, and who would like a bit of guidance in what to look for when choosing an API.
Stream Processing API Design Aspects
Before I get started on the design analysis I want to list the aspects of stream processing API design that I have come to realize are important. These design aspects are:
- Topology
- Feeding
- Forwarding
- Triggering
- State
- Feedback
- Concurrency Model
I will explore different design options and their consequences in the following sections.
Topology
One of the more commonly seen design choices for stream processing designs is, to structure the stream processing components as a graph of components working together. Each component gets a record in, processes it, possibly transforms it, and then outputs 0, 1 or more records to the following components in the graph. Here is a simple example illustration of such a stream processing topology:

The original motivation for this kind of stream processing API design came from APIs designed to process large amounts of objects or records easily, like the Java Stream API. Here is an example explaining the motivation:
Imagine you have millions of Employee objects (or records) in a list, and you need to:
- Find the Employee objects representing employees that are middle managers.
- From these objects, calculate total and average salary for this group of employees.
A straightforward way to implement this requirement would be to first iterate the list of Employee objects, and add all Employee objects that represent middle managers to a new list. Afterwards we can iterate this list of middle managers and calculate their total and average salary. This implementation is illustrated here:

Notice how you first have to iterate all the Employee objects once, just to find the Employee objects matching the criteria. Second, you have to iterate the list of Employee objects matching the criteria, and perform the calculations. In the end you will have iterated more than the original list of elements (original + filtered list).
Imagine now that you need to perform the same calculations, but this time for Employee objects representing non-managers. Again, first you need to iterate the whole list of Employees to find the matching Employee objects, and when you have found those, iterate that list and perform the calculations.
In a naive implementation of the above 2 requirements you will have iterated the original list 2 times (once to find middle managers and once to find non-managers), and iterated each of the filtered lists once. That's a lot of repeat iteration of what is essentially the same objects!
Instead, you could build an object processing graph, iterate the original list of object once, and pass each object to the graph for processing. Here is how the calculations mentioned in the example above could be structured as a graph:

Using this design, the objects are only iterated once. Two filters will forward only the relevant records to the total and average salary calculators.
Stream vs. Batch Processing
Using a graph oriented object processing API makes a lot of sense when you have a list of objects you want to process. A list of objects is also referred to as a batch. A graph oriented design means you only have to iterate the records once. Graph oriented APIs are typically also dynamically composable, making it reasonably simple to implement different types of topologies to suit different processing needs.
In true stream processing, however, you only have one record or object at a time. You will never be tempted to implement the iteration in an inefficient manner as illustrated in the example earlier, since there is always only one object to process at a time. No iteration needed. You can still use a graph oriented design even though you only have one record at a time. You will still get the composability advantage.
However, for many smaller processing requirements using a full graph oriented approach can be overkill. Having a single listener that calculates everything you need to calculate, rather than a whole graph with filters etc. can be easier to implement, and can also perform better.
Additionally, if the graph becomes too big, it can become hard to reason about what it is doing, and you might have trouble providing feedback back up the graph, depending on what type of graph oriented design you use (functional vs. observer based).
There is no clear conclusion here. Just keep in mind that a graph oriented design is not always as beneficial in true stream processing as it is in batch processing. Allow yourself to have an open mind about the possible solution, depending on the stream processing requirements you have. The graph based approach might be appropriate, or it might be overkill. However, you can probably still implement the simple approach with a graph oriented API, if you just only create a single listener / processor that does everything.
Since graph oriented stream processing API designs are both common and popular, the rest of this article will deal with various aspects of graph based designs.
Chain vs. Graph
Different graph oriented stream processing API designs are designed around different types of topologies. For instance, the Java Streams API uses a chain topology, like this:
A chain topology consists of a single chain of processors, each receiving an object or record as input and output an object or record to the next processor in the chain. At the end of the chain you have a single result. The result can be a composite of multiple subresults, but it will be contained inside a single object or record.
Other stream processing APIs allows you to create more advanced graphs of processors. Such a graph can contain multiple results after processing all the records or objects in the stream. Here is an example from earlier in this text:
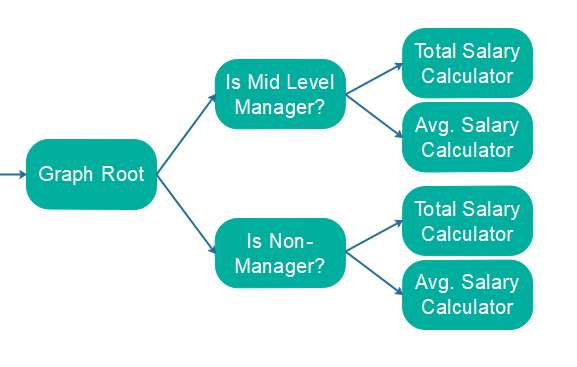
Acyclic vs Cyclic Graphs
Several graph oriented stream processing APIs only allow you to create an acyclic graph, meaning records can ultimately only flow in one direction in the graph. Records cannot "cycle" back up the graph and be reprocessed. In many cases, a cyclic graph is not necessary to perform the needed operations, but once in a while a cyclic graph API could be handy.
Feeding
Feeding refers to how a stream processing API is designed to feed data into its processing topology. For instance, some APIs have a concept of a Stream which you can listen to, or attach various kinds of processors to, to build a topology. But you cannot directly feed a record into the source stream. The stream is locked down to get its data from a specific source. E.g. from a list, or a Kafka topic etc. I refer to this as closed feeding design.

Other APIs makes it easy to feed data into your topology at every step of the topology. During normal operations this may not be necessary for many stream processing use cases, but it can be very useful for some use cases, and also during testing. Being able to feed data into the topology at every node in the graph makes testing much easier. I refer to this as an open feeding design.

Forwarding
Forwarding refers to how a stream processing API is designed to forward data in its stream processing topology, from one processor to the next. There are many ways to design forwarding, but typically forwarding designs fall into the following two categories:
- Static Forwarding
- Dynamic Forwarding
Static and dynamic forwarding are not necessarily hardly separated categories. You can have designs that are "semi-dynamic" (or "semi-static" depending on your choice of nomenclature). Maybe you can think of these two categories as different ends of a spectrum.
Static forwarding means that a given processor can only forward a message processed, or the result of a message processed, to one (or more) predefined processors. This was made static when the topology was created. Once created the topology is static (or hard to change, at least).
Dynamic forwarding means that a given processor is free to choose what processor (or queue which subsequent processors can listen to) forwards the result to. Or, at least it has a higher degree of freedom to choose, if not 100% free choice is possible.
Triggering
Triggering refers to how processors in stream processing API topology are activated (triggered). Triggering mechanisms tends to fall into one of these categories:
- Data Triggering
- Non-data Triggering
Data triggering is the most common triggering mechanism for stream processing APIs. Data triggering means that the processors in the stream processing topology gets triggered by the data that is sent through it. A processor method is called with the data to process, and the data flows through the topology from there.
Non-data triggering means activation of a processor based on a non-data event. For instance, you might want to call a processor every 5 minutes. That would be a time based non-data triggering of that processor.
Non-data triggering is very useful. For instance, imagine a processor that collects incoming data in a buffer, and then write the data in a single batch to disk or database every 60 seconds. If you have a steady flow of data you can trigger the write to disk / database by the incoming data. However, if the flow of data through the topology is not steady, you need to trigger the writing explicitly using a non-data trigger.
Non-data triggering is also very useful for collecting monitoring metrics from your processors. You can collect information about how many messages / records that have passed through each processor during a given time period.
State
State refers to how processors in a stream processing API topology handle state. By state I mean both state kept in memory inside the processors in the topology, and state kept outside the processors - e.g. in a database.
Some stream processing APIs are designed to use only stateless processors. This is typically true for functional stream processing designs - e.g. the Java Streams API and Kafka Streams. Please note, that even if these APIs are intended to use stateless processors in their topology, it is still possible to plugin stateful processors. It's just that the concurrency model of these APIs use a shared state concurrency design - exactly because they do not expect their processors to have state. Thus, if you plugin a stateful processor, you will have to make the state access thread safe yourself.
Other APIs are designed to allow stateful processors - for instance by using a separate state concurrency model. Stateful processors go against all the advice in functional programming (where each processor is just a stateless function), yet stateful processors are really useful sometimes. Being able to have cache objects internally between calls to the processor can improve performance. State is also necessary when e.g. counting how many records have run through the topology. State is also useful for feedback back up the topology (see next section).
Feedback
By Feedback I mean feedback back through a topology, from processors later in the the topology back up to processors earlier in the topology.
Imagine a simple topology consisting of the following processors:
- Mapper: Convert from A to B.
- Filter: Accept 10 first of B matching some criteria.
Imagine that the conversion from A to B is costly in terms of CPU resources. In that case it would be useful for the filter that filters the converted B's to be able to give feedback up through the topology, to tell that 10 B's have been accepted, so no more A's need be converted to B's. Here is how the changed topology could look:
- Filter 1: Accepts all A's until otherwise notified.
- Mapper: Convert from A to B.
- Filter 2: Accept 10 first of B matching some criteria.
After 10 matching B's, notify Filter 1 to not accept anymore A's.
To implement at topology requires that the processors can be stateful.
An alternative to stateful processors would be a topology that can be changed dynamically at runtime. In the example above, Filter 1 could be added when Filter 2 realizes no more A's need to be converted to B's.
Concurrency Model
The concurrency model of a stream processing API refers to how the API is designed to enable sharing the workload between multiple threads. There are several ways to design a concurrency model, as I have explained in my Concurrency Models Tutorial. When it comes to stream processing APIs, it is typically the concurrency model of the topology that matters. Does the topology use a shared state or separate state concurrency model? Etc.
For instance, a stream processing API might be designed to have multiple threads execute the same topology. That essentially leads to a shared state concurrency model. Kafka Streams is designed like that. And - it's an annoying design.
Alternatively a stream processing API could be designed to create an instance of the topology for each thread executing it. Thus, each thread gets its own copy of the topology to execute. This leads to a separate state concurrency model.
It's important that you find out exactly what concurrency model the stream processing API of your choice is using. Otherwise you risk creating a topology that is not thread safe.
More coming soon...
| Tweet | |
Jakob Jenkov | |










