Data Streaming Storage
Jakob Jenkov |
Data streaming can use quite a lot of storage depending on how your data streaming pipeline is designed. In this data streaming storage tutorial I will go through the different factors that impact the storage usage of a data streaming pipeline.
Factors Influencing Data Streaming Storage Consumption
The factors that influence data streaming storage consumption are:
- Original, unique entity count and size (E)
- Change frequency of entities (F)
- Replication factor (R)
- Data stream processing topology (T)
The final formula becomes something like:
F * E * R * T
I will explain each of the factors in more detail the following sections.
Change Frequency
Every time an entity in your domain changes, a change event is fired. Depending on how you structure your data streaming system, an event may contain a full copy of the data that has changed. In that case, each change leads to another copy. Thus, a single entity that changes every second will lead to 86,400 changes per day, and 2,592,000 changes in 30 days.
I have denoted Change Frequency with F (Frequency of change).
Entity Count and Size
The number of entities changing impacts how much storage your data streaming solution needs too. If your system has 1,000 customers who change their information once a year, you will get 1,000 records in the data stream representing the changes. Similarly, if you have 10,000 customers changing once a year, you will get 10,000 records representing the changes each year. If the customers change twice a year, you will end up with 20,000 copies per year.
As changes to an entity typically result in a new copy of the entity, the size in bytes of the entity also plays a role in how much storage the new copy requires.
Replication Factor
It is common to have data streams replicated to mitigate the risk of disk failure. For instance, it is not uncommon to have 2 or 3 copies of the data stream. That means, that for each record in the data stream there are 2 or 3 copies in total including the replicas.
Data Stream Processing Topology
The data stream processing topology plays a significant part in how many copies of each record you get for each single change of a record. By topology I mean how the full data stream processing "pipeline" is structured. There are two primary factors of the stream processing topology that impact the number of copies:
- Topology length
- Topology composition
Each of these two factors will be explained in the following sections.
Topology Length
By topology length I mean the number of hubs in the processing pipeline. A hub is typically a stream processing application which reads a record from one stream and produces one or more records on another stream. Look at this illustration of a data stream processing pipeline:
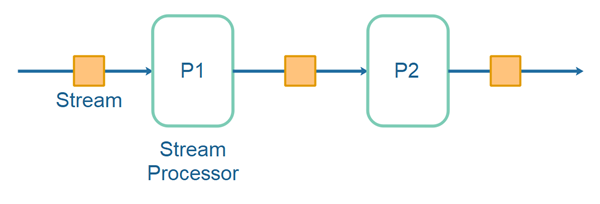
The number of hubs in the above stream processing topology is 2. That results in one original copy of the data, plus one additional copy produced by each of the hubs (stream processors). The total is 3 copies. The length of the stream processing topology thus influences how many copies of data are produced.
In case the records are events, perhaps one event leads to other events produced by other stream processors. Thus, a single original event might lead to several derived events.
Topology Composition
The topology composition I mean how the stream processors compose output records from input records. Look at the following stream processing topology:

Notice how each hub in the topology composes a new output record by joining two input records with each other, possibly storing records in an internal table to make the join possible. I have explained more about this in my data stream join tutorial.
Notice that there are only 4 original input records, but because they arrive in the streams at different times, the stream processors produce one output record for each input record. Some of these output records are composed of multiple input records, and thus result in more copies of the original records. Notice especially how many copies of the original records are produced on the final output stream.
Imagine what happens if the red record changes, and a new copy is written to the end of the red original input stream. That will result in another record composed of the red and yellow record from the first stream processor, and another record composed of the red, yellow, blue and green record. Thus, a change to a single record (the red record) resulted in 2 extra copies of the yellow record, and 1 extra copy of the blue and green record - a total of 7 copies of record, because 1 record changed. This is illustrated here:
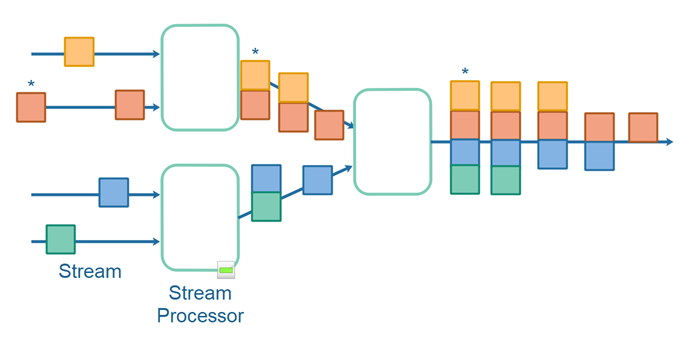
The changed red record and the records derived from that change are marked with a * in the illustration.
Data Streaming Storage Summary
As you can see, once you start using data streaming you can easily end up with many copies of the original data you are recording changes to. There are several factors which impacts how much storage your stream processing system ends up using. This may, or may not be a problem for you. At least now you are a bit better prepared to make some sane storage calculations, so you have an idea about how much storage you will actually need.
| Tweet | |
Jakob Jenkov | |










